Search AI Products and News
Explore worldwide AI information, discover new AI opportunities
- ✓AI News
- AI Tools
2025-03-06 10:52:45.AIbase.
IBM Launches Compact AI Model Granite 3.2, Emphasizing Efficient Inference and Practicality

2025-02-20 16:44:24.AIbase.
VLM-R1 Leads a New Era for Visual Language Models as Multimodal AI Achieves New Breakthroughs

2025-02-08 16:45:45.AIbase.
IBM Launches Visual Language Model Granite-Vision-3.1-2B, Effortlessly Analyzing Complex Documents

2025-01-20 14:04:10.AIbase.
MIT and DeepMind Research Reveals Why Visual Language Models Struggle with Negation

2024-11-27 15:56:10.AIbase.
Hugging Face Launches 2B Parameter Visual Language Model SmolVLM: Runs Quickly on Ordinary Devices

2024-11-08 13:59:34.AIbase.
Compact and Powerful! Pocket-sized Visual AI Model Moondream2: Just 1.6 Billion Parameters, Runs on Mobile Phones

2024-10-29 11:08:05.AIbase.
Moondream Raises $4.5 Million to Launch a 1.6 Billion Parameter Efficient AI Model with 5K GitHub Stars

2024-10-18 10:11:29.AIbase.
Small but Powerful! H2O.ai Launches New AI Visual Models to Outperform Tech Giants in Document Analysis

2024-09-05 11:28:29.AIbase.
Alibaba Cloud's Tongyi Qwen Responds to Github Page 404: In Contact with Officials

2024-09-02 14:21:57.AIbase.
Tongyi Qwen Open Source Visual Language Model Qwen2-VL API Available in 2B and 7B Sizes
2024-09-02 11:17:38.AIbase.
NVIDIA Launches New Visual Speech Model NVEagle, Capable of Chatting with Images
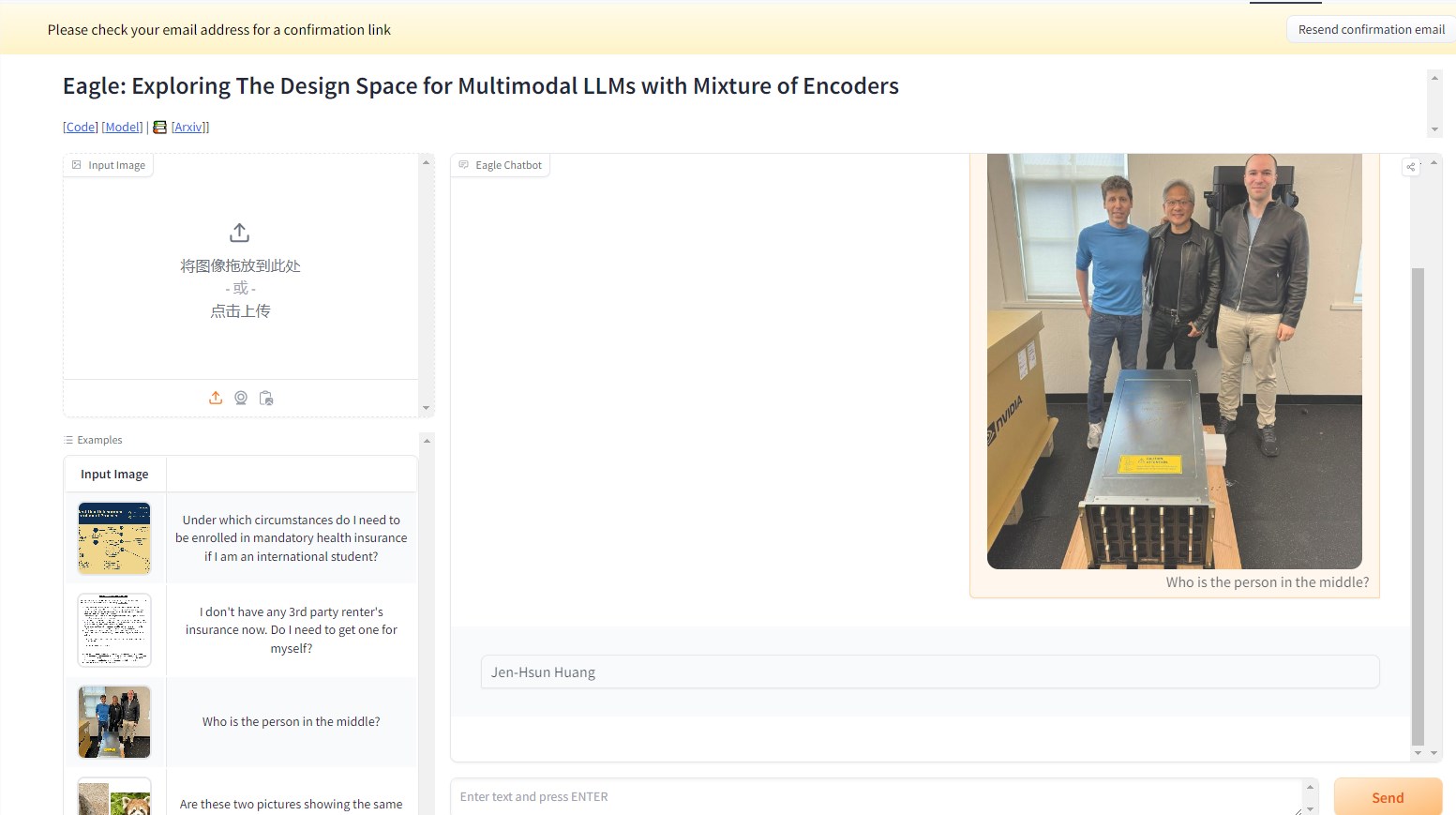
2024-07-17 13:47:02.AIbase.
智源AI has unveiled EVE, its latest generation encoder-less vision-language multimodal large model.
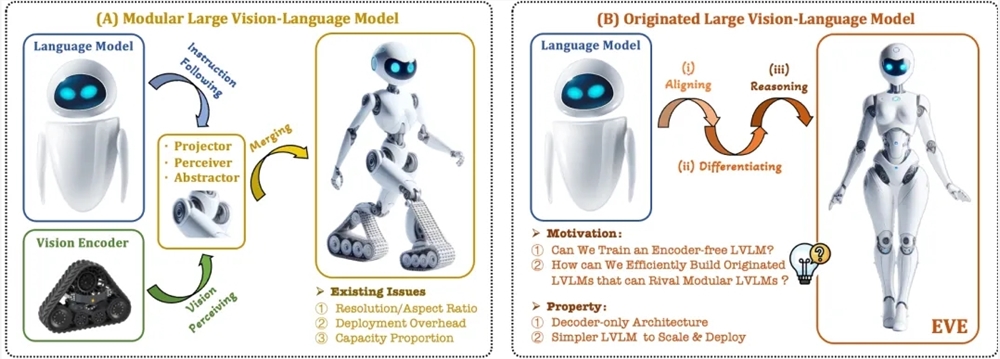
2023-12-27 15:35:05.AIbase.
Tsinghua University Develops New Visual Language Model CogAgent to Enhance GUI Understanding and Navigation
2023-12-21 08:37:02.AIbase.
Zhipu AI Open-Source Visual Language Model CogAgent Supports GUI Graphic Interface Q&A
2023-10-27 09:02:48.AIbase.
Google Releases Lightweight PaLI-3 Visual Language Model Achieving SOTA Performance
2023-10-25 15:39:22.AIbase.
Xi Xiaoyao Technology Talk | Stop Saying GPT-4V is Amazing! It Can't Even Recognize Peking Duck, Can You Believe It??
2023-08-25 14:08:54.AIbase.